Technology Leaders
Build a trusted data backbone for your intelligent enterprise.
Whether you are modernizing your data stack or deploying agentic workflows, Reltio Context Intelligence Platform™ provides the trusted, governed data foundation critical to realizing business outcomes today and tomorrow.

Your systems were designed for humans. That won't work in the age of AI agents.
Digital transformation has taken place within today’s app-centric architectures. AI transformation demands a shift to data-centric architectures, where AI workflows are fueled by trusted context delivered in real time.
AI agents need context—and context is built on unified data.
When data is siloed and unreliable, teams intervene in every workflow and scale stalls. True data harmonization and unification, not simple aggregation, builds enterprise-wide context that lets you deploy AI agents at scale with confidence.
Actionable context comes from trusted data enriched with business meaning.
Graph-based semantics are at the heart of actionable context. 360-degree views of relationships and attributes—enriched with interactions—make context robust enough for autonomous decisions and machine-interpretable for AI workflows at scale.
Legacy MDM can’t keep up with modern demands.
The business demands more agility and faster innovation from your teams. Modern data unification capabilities are critical to lowering total cost of ownership, increasing speed to value, and ensuring that your data capabilities can respond to changing business priorities fast.
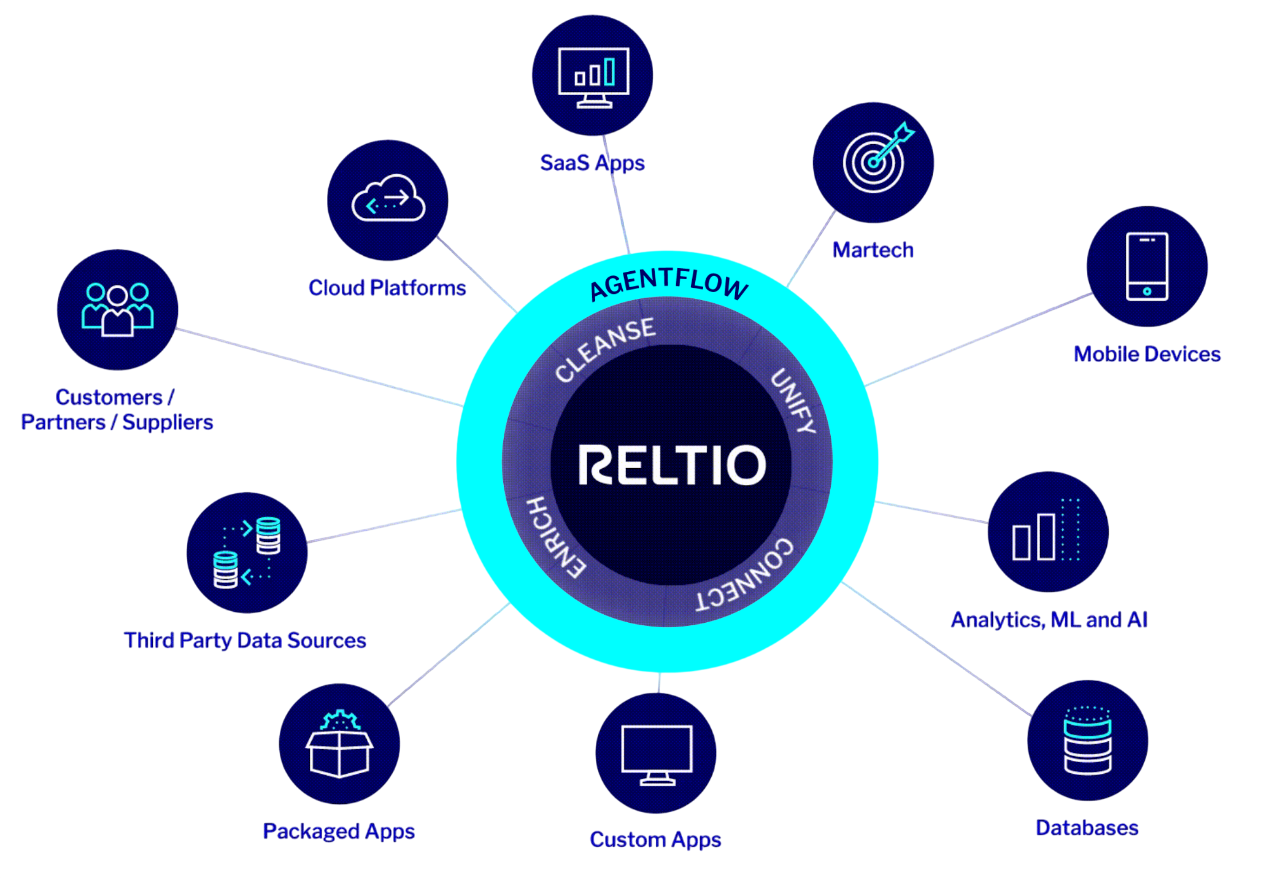
Build a system of context to deliver today and scale tomorrow.
Our platform continuously harmonizes, unifies, and enriches data and metadata across sources, domains, and formats—including unstructured data—in real time, feeding the Reltio Intelligent Data Graph to provide an AI-interpretable understanding of the business for the whole enterprise.
It activates this trusted, rich context to AI agents and operational systems in real time and at scale—in a governed, secure framework with policy-aware access controls, built-in privacy management, auditability, and lineage.
Build a trusted, AI-ready enterprise data foundation that's governed.
We unify structured and unstructured data across the enterprise through prebuilt integrations and industry-leading entity resolution that augments robust rule-based matching with pretrained LLMs. Dynamic survivorship creates reliable golden records for confident, data-driven decisions.
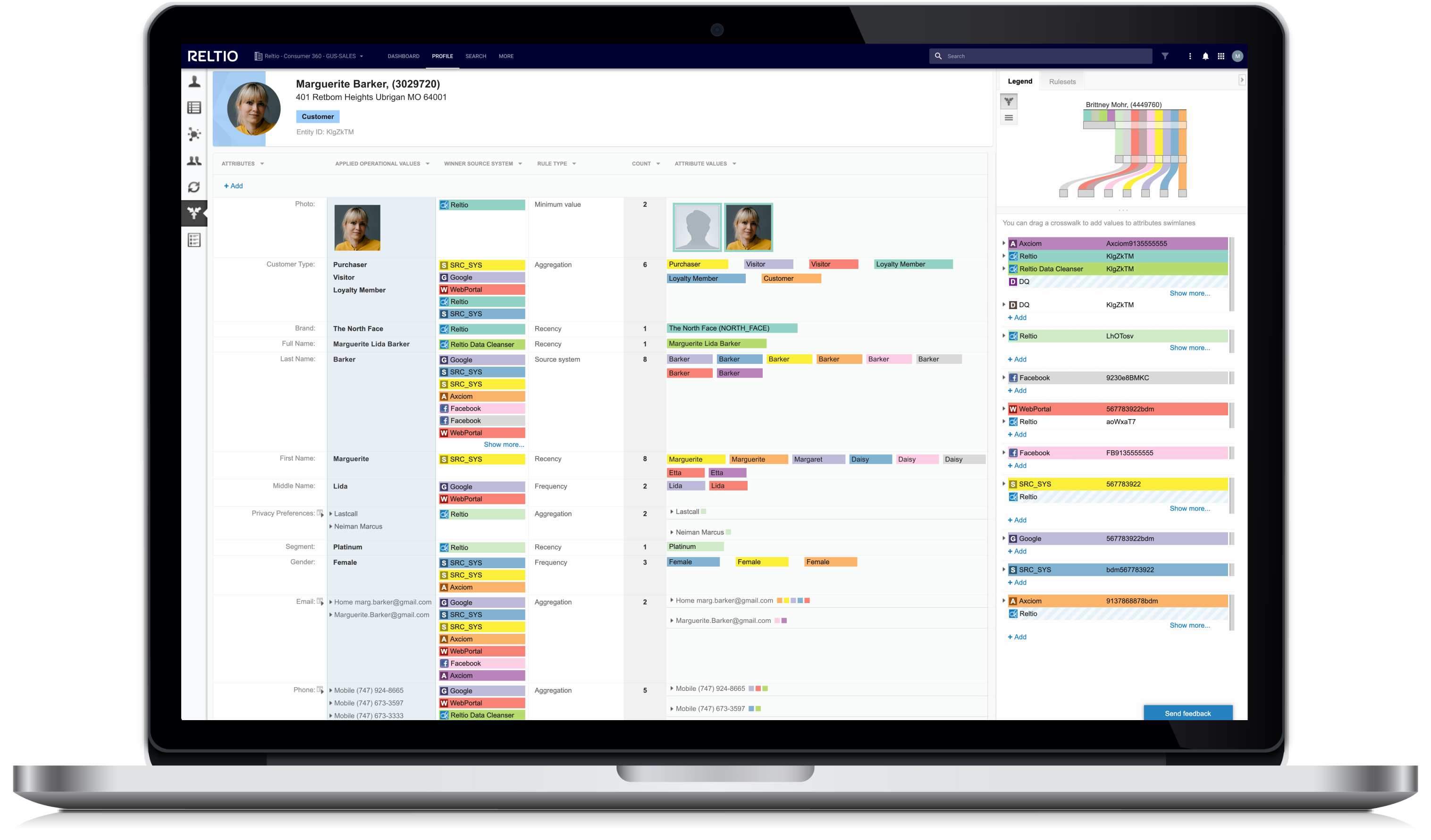
Create, use, and reuse cleansed, governed 360° profiles for any domain.
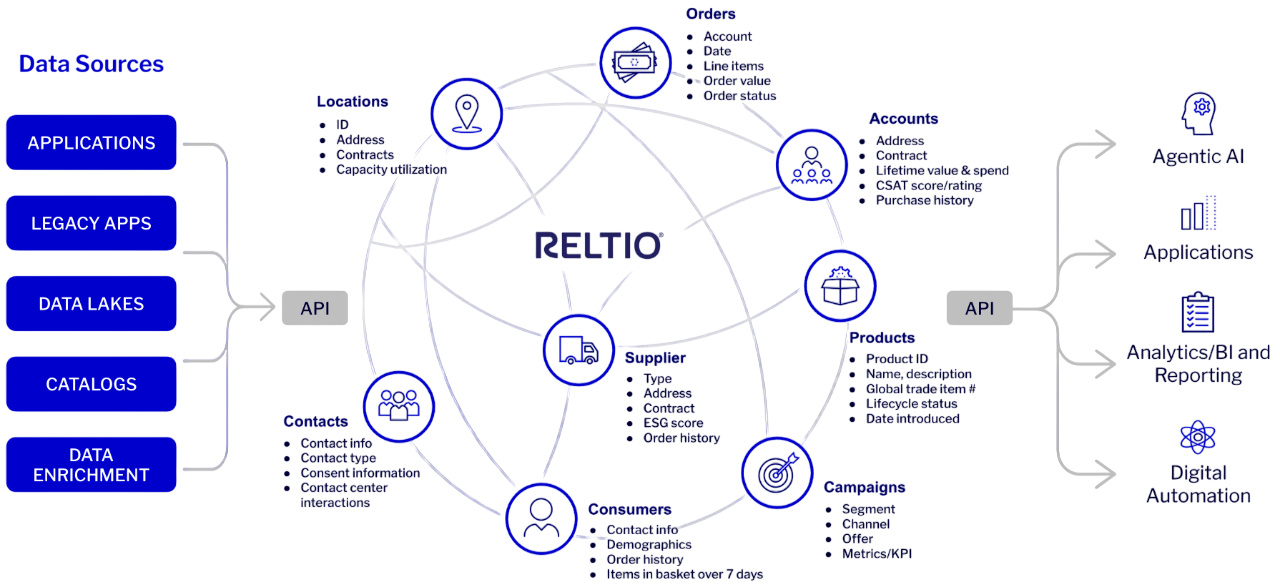
Our platform unifies and enriches data across customers, products, suppliers, and other domains using a canonical model that captures hierarchies, interactions, and unstructured data. The result? Reusable data assets for speed and quality in all enterprise use cases.
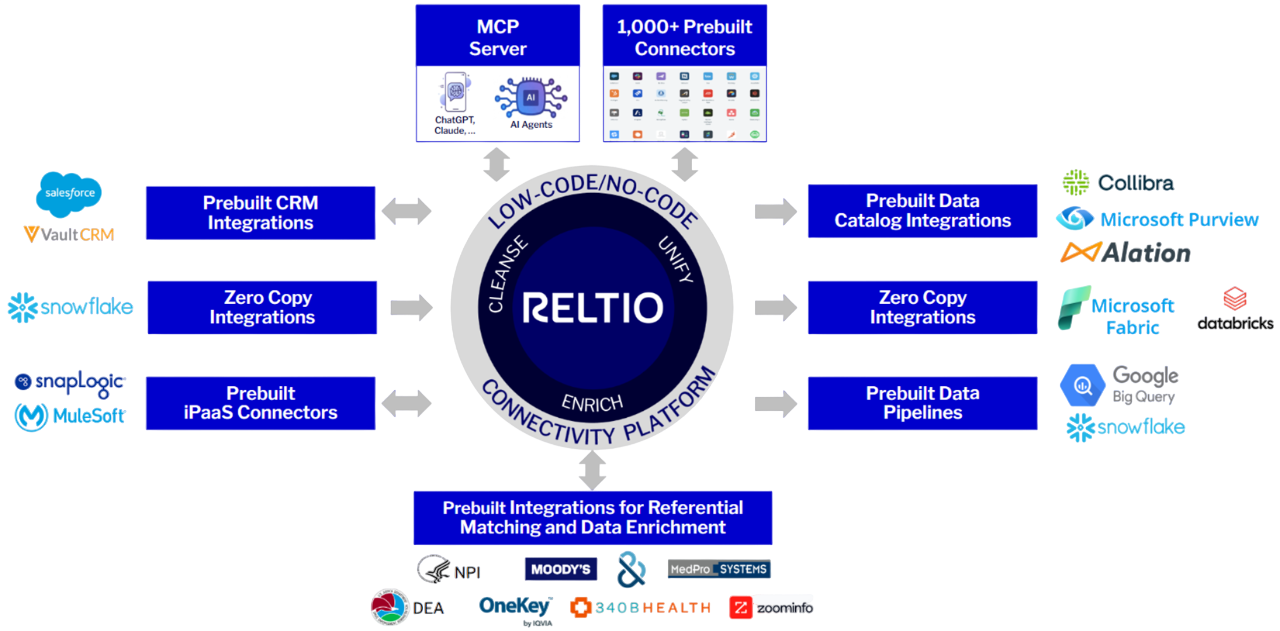
Faster time to value with prebuilt, scalable integrations.
Accelerate time to value with 1,000+ prebuilt connectors for apps, data catalogs, and enrichment sources, plus zero-copy integrations to cloud data warehouses. Reltio MCP server provides governed, real-time context to AI agents and LLMs.
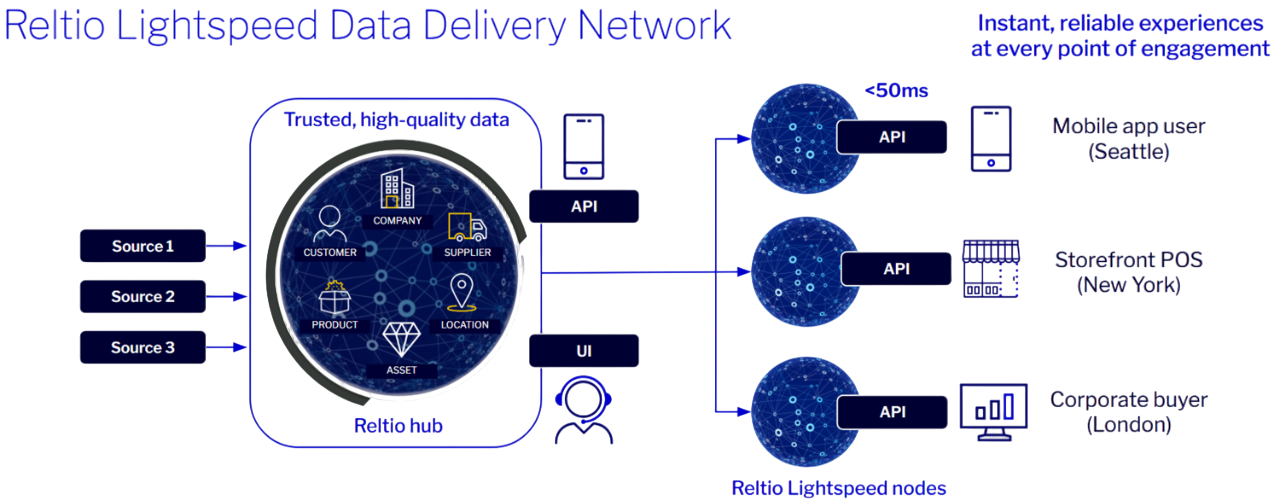
Get ultra-low latency access to trusted data globally.
Instant access to trusted data at the edge with Reltio Lightspeed Data Delivery Network using a high-performance, distributed network designed to deliver reliable business-critical data globally with ultra-low latency, enabling agentic AI at the point of engagement.
Improved data team productivity with agentic UX and purpose-built agents.
Evolve enterprise operations with Reltio AgentFlow—the agentic AI platform that provides purpose-built, context-aware, autonomous agents. Powered by trusted, context-rich data and accessible via an intuitive UI, our agents are designed to operate with real-time data and deliver real outcomes for real jobs-to-be-done.

Partner with a trailblazer.
We're a Leader in Forrester Wave 2025 for Master Data Management
77%
data quality improvement
£3.6M
annual cost reduction
~10X
increase in data steward productivity
Why technology leaders choose Reltio.
Our platform was built for the operational reality of agentic AI. WIth Reltio, enterprise leaders build the data foundation that they need to deliver today and tomorrow.
Semantic Reltio Intelligent Data Graph™.
At the heart of our platform is the only enterprise-wide data graph that maps the interconnections between entities, attributes, interactions, and unstructured data—then activates it across AI and operational systems.
Open, API-first ecosystem.
Connect across your ecosystem with 1,000+ prebuilt connectors, event streams, and zero-copy options. Low-code pipelines onboard new sources fast, enrich data, and publish governed data to apps, analytics, and AI.
Enterprise-grade security and control.
Get built-in governance, lineage, consent, and security controls—including RBAC, encryption, and HA/DR—for resilience and compliance. Relationship-aware data provides trusted context that safely powers operations and AI.

“We were promising three things: we were going to get better performance, the environment was going to become more stable. And we’re going to be spending about 80% of our time talking about innovation and 20% of our time doing the operations work. So that was what we had promised. And the nice thing is that it has essentially come to fruition.”
Chad McCord
Senior IT Manager, Master Data Management

Fueling transformation and growth for every industry.
Ready to
see it in action?
See how the Reltio Context Intelligence Platform can give you the speed and flexibility you need to accelerate the value of your data and maximize its impact every day.