How Machine Learning Helps Align Data at the Speed of Business

As businesses try to harness their many siloed sources of data by implementing master data management (MDM), many find that aligning the various data sources to produce a “single source of truth” is much harder than it appeared at first. Yet ensuring data alignment and quality is critical to the MDM effort, whether it’s for the customer, product, vendor, or other master data. Business decisions based on bad data can not only be time-consuming but also extremely costly. According to Gartner research, “the average financial impact of poor data quality on organizations is $9.7 million per year.” Businesses are investing in MDM solutions to build a unified, reliable, and real-time data foundation to power their business operations and insights. The “Match and Merge” process plays a key role to align data across systems, deduplicating records that match, and merging the matched records into a single source of truth. Traditional MDM systems can make this cumbersome, time-consuming, and prone to errors. To overcome these challenges and ensure high data quality at scale, next-generation MDMs are using machine learning.
Let’s briefly examine the traditional processes of how records need to be matched and merged to form this unified view of the entities within an MDM platform and then see how machine learning technology can help optimize the matching process to improve the results and produce better quality data at scale. The machine learning approach is one of the most innovative master data management trends your business will want to get ahead with. You will see why the “match and merge” of traditional systems aren’t adequate for today’s high-speed digital, data-intensive business environments.
Traditional Match-and-Merge Doesn’t Work for Today’s Enterprises
Traditional methods of matching are performed based on a set of instructions coded in the underlying legacy MDM platform. Configuring match rules here requires a series of time-consuming steps iterated until all stakeholders agree on the configuration that should be used for matching. Even the most efficient execution takes weeks or even months to complete across a process that includes most of these steps:
- Gather the matching criteria to create the rule (example: first name, middle initial, and last name must match exactly to be considered a match).
- Run the match rule and review the results for the completeness and quality of the data set to assure the desired attributes are available to be matched. If we run the above rule and find that 70% of the records have no middle initial, we would need to rethink our initial matching criteria, perhaps by adding a telephone number or zip code.
- Data profilers, solution architects, and data stewards repeat the above steps until business users agree with the results. This process is then converted to a set of instructions for the system to execute to determine matches.
- A technical person (perhaps a solution architect or configurator) configures the matching process by designing matching rules to meet the business user’s requirements using options supported by the underlying MDM platform. This includes identifying the right pairs for matching and executing the match process to determine which pairs actually do match.
- Business users review the match results and may request additional attributes or other changes to produce the desired results. Any change in requirements, of course, means a change in configuration.
- Iterating the match configuration process based on user feedback continues until the business requirements are met.
- After this lengthy process to fine-tune the match configuration and deploy the rules, the business users can finally see match results across the entire data set.
Not only is this process quite cumbersome and time-consuming, but also:
- Patterns that are not accounted for in the requirement would likely generate wrong matches or miss important match pairs.
- Errors in configuration or coding would also produce errors in matching.
- Finding the perfect balance between what can be automatically merged by the system vs. the pairs that need manual resolution can be very challenging.
- And, of course, as new data sources are brought online, much of this process may need to be done again.
In short, traditional match-and-merge processes do not work for today’s businesses that need to deal efficiently with large volumes of data coming in from a variety of sources. The old processes aren’t fast, flexible, or reliable enough to ensure quality data. However, the more modern, machine learning approach to matching able to provide better, more reliable results.
Machine Learning Optimizes the Process to Produce Better Results Faster and At Scale
Machine learning (ML) is generally recognized as being particularly good at pattern recognition, learning from examples, and generalizing behavior over and above what existed in the original examples. If you think ML would be perfect to streamline merge-and-match processes, you would be correct. “Machine learning has proven its potential in real-world business settings: With an ML-enabled data curation system, the curation costs for data cleansing, data transformation and deduplication could be reduced by 90%” (source: Stonebraker, Bruckner, and Ilyas 2013). However, it’s not just about costs–machine learning can produce more reliable and consistent results compared to highly manual processes of traditional methods of matching. And, it is able to apply what it has learned to larger, broader data sets, enabling easier scaling.
Organizations that recognize the value of cloud-native, multi-domain MDM for operations and analytics at today’s speed of business have a real ally in Reltio Match IQ, an add-on for Reltio Connected Data Platform. Reltio Match IQ draws on the power of machine learning to get smart matching and merging of data from multiple data sources. Match IQ’s machine learning speeds the matching process by deriving matching requirements automatically during “active learning” training. It offers a consistent way of matching and merging data for better quality, reliability, and business value. Match IQ replaces the traditional multi-step process of defining, profiling, configuring, and iterating matching requirements that can take weeks. Match IQ’s machine learning-driven process can deliver final match models in as little as a few hours — and, without the need of IT.
Ensuring the quality of data is essential for delivering consistent, targeted, and timely personalization across marketing channels, as well as for powering insight-ready data to support business strategies and tactics. Reltio Match IQ helps you create cleaner, more robust, and accurate data profiles despite large data volumes or limited data experts. It leverages a machine learning model to expedite matching and improve the quality of data with less dependency on IT. Since Match IQ is the add-on functionality of the Reltio Connected Data platform, it eliminates the need for additional products for address validation and data quality as is often the case of legacy MDM.
Reltio Match IQ Makes Matching & Merging Records Easy
Reltio Match IQ empowers business users to easily set up and deploys the match-and-merge operation. Here’s an overview of the machine learning matching process:
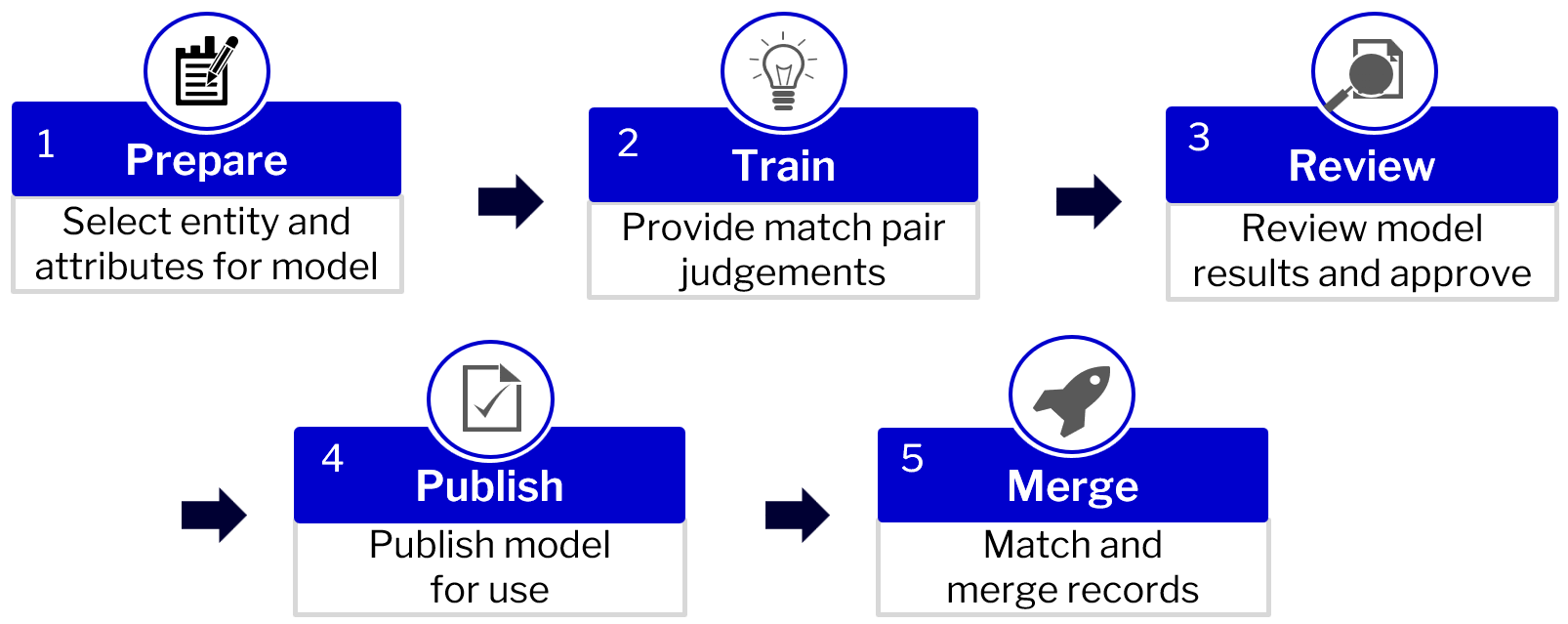
An intuitive user interface guides business users through the step-by-step process. Here’s how it works:
- Once the Reltio Match IQ subscription is purchased (assuming data sources are already available), the user simply selects the data entity and attributes needed to determine whether matches exist. For example, the user might select customer records with attributes such as name fields plus address and telephone.
- Next, the user trains the business model using an active learning process. This involves reviewing pairs of records presented by Match IQ. For each pair, the user selects “Match,” “Not a Match” or “Not Sure.” Users can tune the accuracy of match desired (i.e., exact or fuzzy matching) by simply approving similar, but not exact, matches. For example, matching Dick Jones and Richard Jones would enable fuzzy matching of first names.
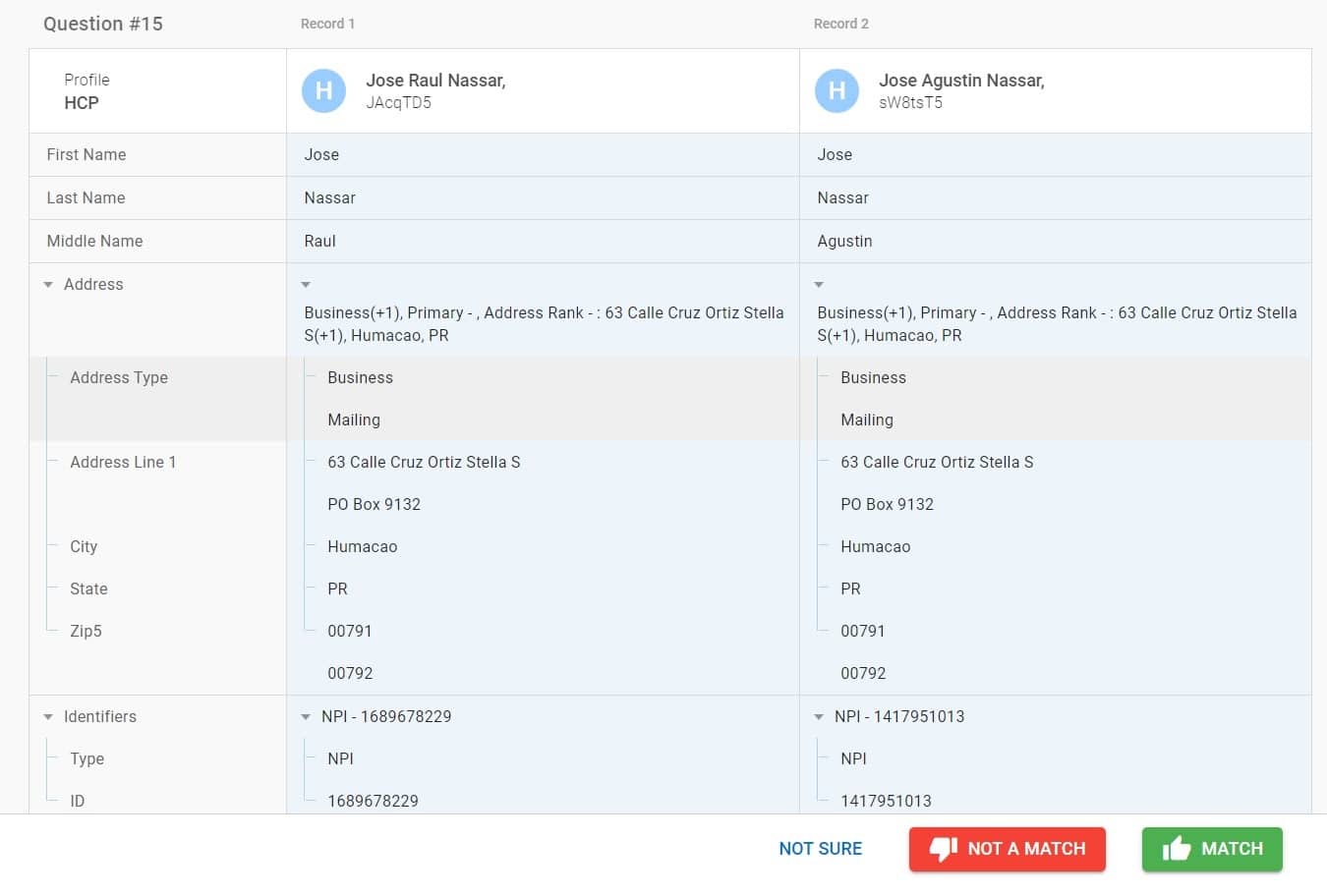
- As users confirm the matches, machine learning adjusts the matching model and generates additional match pairs to further refine the model. For example, if the requirement is to match first, middle, and last name, yet the middle name is missing but another attribute like a birthday is a match, the user can accept birthday as an alternate match parameter, and Match IQ will learn and adjust the model accordingly. This is all done without the traditional back-and-forth between the business user and the IT configurator. It’s not only faster, but nothing gets lost in translation.
- After training, users can review the model for the quality of matched pairs. Once confident with the scenarios captured, users can end training, then download and review match results. The downloaded file shows a relevance score for each record pair. The higher the score, the more likely that a match exists. If needed, the model can be trained with additional match pairs.After the business user is satisfied, the data steward, via a purpose-built dashboard, reviews the results and approves or adjusts the model by additional training.
- Once approved, the data steward publishes the model. During publishing, the data steward selects whether the model can be used with internal and/or external data. In addition, publishing settings include which records will be merged based upon the relevance score (e.g., merge records with a relevance score of .8 to 1).
- Once the model is published, the match-and-merge action takes place on an automated basis. Through the power of sophisticated machine learning, Match IQ reduces the time it takes to monitor, manage and improve match quality from weeks and months to days.
In the Reltio scenario, users can also access data from external files and compare it with data in Reltio tenant records before merges are made. One common use case is for matching an external file (e.g., a new list of marketing records) that needs to be compared to records in a Reltio customer’s existing MDM to see whether they already exist. Again, users don’t need to involve IT to handle this task. Match IQ will generate two separate files: one, a list of records with no matches; the other, a list showing the matched records from the original list and the Reltio tenant.
Reltio’s Unique Machine Learning Matching
No other solution does what Match IQ can do. While other match tools may use machine learning, their output is a non-flexible match rule which ultimately needs to be maintained by IT or application experts. Since Match IQ doesn’t generate a fixed configuration, business users can continue to retrain the model for more precise matches. Match IQ derives matching requirements based on active learning, so there is no need to understand how to configure rules at all. This empowers business users who understand the data matching process to train the model and review matches without relying on IT to configure or code match requirements using the underlying technology.
Overtime Match IQ users may not even have to go back in and retrain the Match IQ model. Instead, users would be able to do this incrementally through the Data Steward Screen. This ensures Match IQ model will continue to learn even after it is published and in use.
With Reltio Match IQ, enterprise teams can focus their time and efforts on improving customer experience strategy and operational efficiency, without having to worry about data quality.
Ready to get started with Reltio Match IQ. contact your CSM or request for Demo.
