What is Data Consolidation?
Data consolidation is the practice of integrating data from multiple sources into a single target such as a data warehouse to be used by data consumers. Recent surveys have estimated that US enterprises on average access over 400 data sources in their operations. Furthermore, 20% of these enterprises rely on over 1,000 sources, emphasizing the need for a comprehensive data consolidation management plan.
The consolidation of data can be performed by designing a data pipeline that ingests data, transforms it into a suitable format, then stores it for projects like data analysis, data visualizations, or machine learning. The consolidation practice itself is referred to as Data Integration and Interoperability (DII).

Understanding Data Consolidation
Data consolidation is a practice and a concept that is less than standard within industries. Standard data management frameworks, like DAMA Data Management Framework, reference activities and objectives of data consolidation underneath Data Integration and Interoperability (DII) but do not refer to it as a practice itself.
Instead, data consolidation floats between the ideal simple definition above (the practice of integrating data from multiple sources into a single target) to the complicated reality that data is vast and its consolidation is complex for most enterprises. Because most organizations encompass potentially thousands of data stores, the effective and efficient management of the data movement processes between internal and external stores is a central priority and responsibility. Improper management can lead to data corruptions and subsequent business consequences.
To further add to the complexity is the operational practice of purchasing vendor solutions which then must be integrated with each other— each with their own master data, transaction data, and reporting data to be consolidated with the other systems. This complexity alone is the greatest reason for architecting data consolidation/integration processes rather than building point-to-point systems that can end up in millions of interfaces and overwhelm system resources.
The Challenges of Data Consolidation
Complexity is the main challenge to overcome when trying to achieve an effective data consolidation. Subsequently, three challenges stand in the way of teams attempting to execute an effective data consolidation strategy.
- Limited Time: IT projects trade time today for future time. Effective and efficient data operations can reclaim time in the future by managing and preventing data corruptions. But these processes must be set up properly, which costs time to ensure, if not incorrect data consolidation processes may cause more problems than prevent.
- Limited Resources: Resources include compute and storage but also human resources. Filling the data team with the right skills to perform data consolidations is equally as important as having the right infrastructure.
- Security and Compliance Concerns: The nature of data today is such that it is now regarded as valuable as gold, but can be dangerous. For instance, often data in an enterprise can be used to personally identify someone, so Personally Identifiable Information (PII) must be guarded to protect consumers, but also, critical data that is to be purged must be done so correctly to ensure this privacy. And in an overlapping manner, compliance to government data regulations must be followed.
The type of data catalog tool that is best for an organization will depend on their specific needs and requirements. Factors to consider include the size of the organization, the number and type of data assets, and the level of customization and integration required.
The Benefits of Data Consolidation
The main benefit of data consolidation and data consolidation solutions is to reduce the complexity of managing data integrations. With effective and efficient control over data integrations, enterprises can benefit in the following ways:
- Improves Data Quality: High data quality is at the heart of quality business intelligence. By consolidating data, enterprises are able to control data quality, improve it, and ensure useful business insights.
- Foundation for Performing Analytics: Downstream data analytics projects, including machine learning, and data visualizations, build upon the consolidation of data. As new applications embrace data intensive applications, like big data analysis, enterprises will lean on high performing data integration solutions.
- Garner Greater Insight into Business and Operations: Deluged by data, businesses grapple with understanding the forest for the trees. Consolidating data into a single view allows enterprises to step back to see all the business processes fit (or not fit) together, aiding the planning of better business processes, understanding appropriate disaster recovery, and to budget data capacity needs more accurately.
Data Consolidation Techniques
Data consolidation techniques are many, and vary depending on the end use, however, three common data consolidation techniques must be mentioned: ETL, data warehousing, and data virtualization.
ETL
ETL stands for Extract, Transform, and Load, and refers to the basic pattern for processing and integrating data together from multiple sources. This pattern is used in physical as well as virtual executions, and in batch processing and real-time processing. In general, ETL data flows is a term that can be interchanged with data pipeline, however, data pipelines entail more. ETL references only the Extract, Transform, and Load stage of the pipeline.
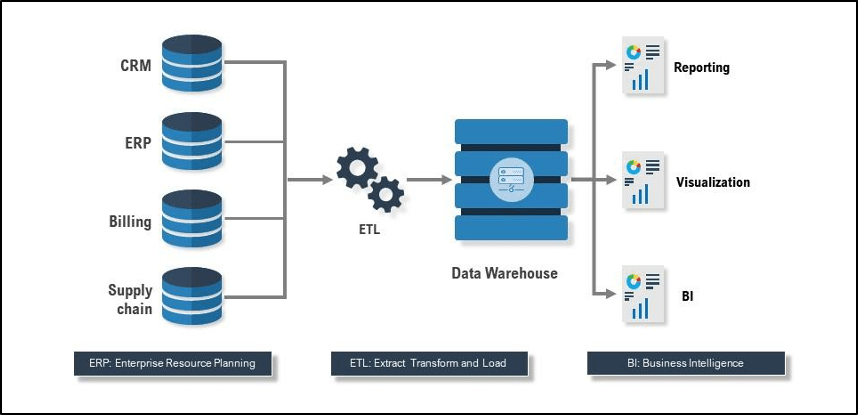
Data Warehousing
An ETL process indicates that data is to be transformed into a suitable format for storage, typically in a data warehouse. This also implies that there are multiple data sources, almost always true. In essence a data warehouse is a physical storage of the consolidated results of an ETL process. However, in its broadest sense, data warehouses store formatted data from multiple sources to support BI, reporting, and visualization purposes.
Data Virtualization
Data virtualization is a method of consolidating disparate data stores in a way other than physical integration. Implementing a data virtualization solution can consolidate disparate data sources, and heterogeneous data sources, as a single virtually unified and accessible database.
Ready to
see it in action?
See how the Reltio Context Intelligence Platform can give you the speed and flexibility you need to accelerate the value of your data and maximize its impact every day.