How Turning Your Core Data into a Product Drives Business Impact

Data drives efficiencies, improves customer experience, enables companies to identify and manage risks, and helps everyone from human resources to sales make informed decisions. It is the lifeblood of most organizations today. Sometime during the last few years, however, organizations turned a corner from embracing data to fearing it as the volume spiraled out of control. By 2025, for example, it is estimated that the world will produce 463 exabytes of data daily compared to 3 exabytes a decade ago.
Too much enterprise data is locked up, inaccessible, and tucked away inside monolithic, centralized data lakes, lake houses, and warehouses. Since almost every aspect of a business relies on data to make decisions, accessing high-quality data promptly and consistently is crucial for success. But finding it and putting it to use is often easier said than done.
That’s why many organizations are turning to “distributed data” and creating “data products” to solve these challenges, especially for core data, which is any business’s most valuable data asset. Core data or master data refers to the foundational datasets that are used by most business processes and fall into four major categories – organizations, people (individuals), locations, and products. A data product is a reusable dataset used by analysts or business users for specific needs. Most organizations are undergoing massive digital and cloud transformations. Putting high-quality core data at the center of these transformations—and treating it as a product can yield a significant return on investment.
The Inefficiency of Monolithic Data Architectures
Customer data is one example of core or master data that firms rely on to generate outstanding customer experiences and accelerate growth by providing better products and services to consumers. However, leveraging core customer data becomes extremely challenging without timely, efficient access. The data is often trapped inside monolithic, centralized data storage systems. This can result in incomplete, inaccurate, or duplicative information. Once hailed as the savior to the data storage and management challenge, monolithic systems escalate these problems as the volume of data expands and the urgent need for making data-driven decisions rises.
The traditional approaches for addressing data challenges entail extracting the data from the system of records and moving it to different data platforms, such as operational data stores, data lakes, or data warehouses, before generating use case-specific views or data sets. In addition, because of the creation of use case-specific data sets that are subsequently exploited by use case-specific technologies, the overall inefficiency of this process increases. One inefficiency arises from the complexity of such a landscape, which involves the movement of data from many sources to various data platforms, the creation of use case-specific data sets, and the use of multiple technologies for consumption. Core data for each domain, such as customer, is duplicated and reworked or repackaged for almost every use case instead of producing a consistent representation of the data used across various use cases and consumption models – analytical, operational, and real-time.
There’s also a disconnect between data ownership and the subject matter experts that need it for decision-making. Data stewards and scientists understand how to access data, move it around and create models. But they’re often unfamiliar with the specific use cases in the business. In other words, they’re experts in data modeling, not finance, human resources, sales, product management, or marketing. They’re not domain experts and may not understand the information needed for specific use cases, leading to frustration and data going unused. It’s estimated, for example, that 20% or fewer of data models created by data scientists are deployed.
Distributed Data Architecture – An Elegant Solution to a Messy Problem
The broken promises of monolithic, centralized data storage have led to the emergence of a new approach called “distributed” data architectures, such as data fabric and data mesh. A data mesh can create a pipeline of domain-specific data sets, including core data, and deliver it promptly from its source to consuming systems, subject matter experts, and end users. These data architectures have arisen as a viable solution for the issues created by inaccessible data locked away in siloed systems or rigid monolithic data architectures of the past. Data fabric decentralizes the management and governance of data sets. It follows four core principles – domain ownership of data, treating data as a product and applying product principles to data, enabling a self-serve data infrastructure, and ensuring federated governance. These help data product owners create data products based on the needs of various data consumers and for data consumers to learn what data products are available and how to access and use these. Data quality, observability, and self-service capabilities for discovering data and metadata are built into these data products.
The rise of the concept of data products is helpful for analytics/artificial intelligence, and general business uses. The concept for either case is the same – the dataset can be reused without a major investment in time or resources. It can dramatically reduce the amount of time spent finding and fixing data. Data products can also be updated regularly, keeping them fresh and relevant. Some legacy companies have reported increased revenues or cost savings of over $100 million.
Trusted, Mastered Data as a Product
Data product owners have to create data products for core data to enable its activation for key initiatives and support various consumption models in a self-serve manner. The typical pattern that all these data pipelines enable can be summarized into the following three stages – collect, unify, and activate.
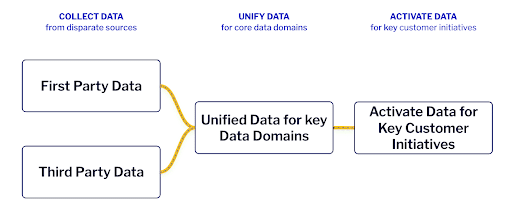
The process starts with identifying the core data sets – data domains like customer or product – and defining a unified data model for these. Then, data product owners need to identify the first-party data sources and the critical third-party data sets used to enrich the data. This data is assembled, unified, enriched, and provided to various consumers via APIs so that the data can be activated for various initiatives. Product principles such as the ability to consume these data products in a self-service manner, customize the base product for various usage scenarios, and deliver regular enhancements to the data are built into such data products.
Data product owners can use this framework to map out key company initiatives, identify the most critical data domains, identify the features (data attributes, relationships, etc.) and the sources of data – first and third party that needs to be assembled – to create a roadmap of data products and align them to business impact and value delivered.
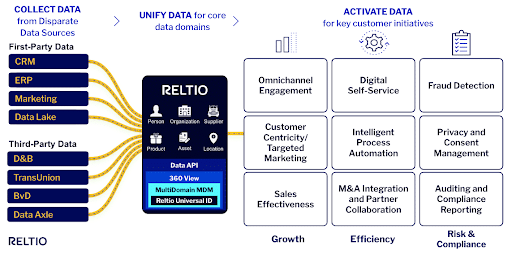
With data coming from potentially hundreds of applications and the constantly evolving requirements of data consumers, poor quality data and slow and rigid architecture can cost companies in many ways, from lost business opportunities to regulatory fines to reputational risk from poor customer experience. That’s why organizations of all sizes and types need a modern, cloud-based master data management approach that can enable the creation of core data as products. A cloud-based MDM can reconcile data from hundreds of first and third-party sources and create a single trusted source of truth for an entire organization. Treating core data as a product can help businesses drive value by treating it as a strategic asset and unlocking its immense potential to drive business impact.
Please check out this webinar for a deeper dive into this topic:
