Agentic AI is forcing a shift from application-first to data-first architecture

In the last decade, most large enterprises modernized by “going digital”—rolling out cloud applications, automating workflows, and exposing APIs. That application-first approach delivered real wins, but it also left behind a familiar residue: duplicated data, inconsistent definitions, brittle integrations, and governance that arrived after the fact.
Agentic AI changes the game because it doesn’t just analyze or recommend—it executes. When software can plan, call tools, move work across systems, and learn from outcomes, the architecture you’ve tolerated for years starts to become a strategic liability. In an agentic world, the differentiator is no longer which applications you own. It’s whether your enterprise can produce trusted context fast enough—and safely enough—for autonomous systems to act.
This is why the next phase of transformation is not “AI-first” as many vendors describe it. It is data-first. Data becomes the operating system for AI-driven execution: the layer that defines identity, relationships, permissions, policy, and business meaning across every channel and system.
Below is a pragmatic point of view—written for CEOs and boards as much as for CIOs and CTOs—on why the shift is essential, what makes it feasible now, and how to sequence investments without boiling the ocean.
What agentic AI really changes
Most executives first experienced generative AI as a faster interface to information: ask a question, get an answer. Agentic AI is different. It is software that can interpret intent, break work into steps, choose tools, take actions in systems of record, and verify outcomes. In other words, it closes the loop from “insight” to “outcomes.”
That leap from chat to action has two immediate implications for enterprise architecture.
First, the center of gravity shifts from user interfaces to orchestration. When agents can navigate across CRM, ERP, commerce, service, supply chain, and bespoke platforms, the workflow is no longer bound to a single application. The “process” becomes a sequence of actions across many systems, coordinated dynamically by an agent layer.
Second, the tolerance for ambiguity collapses. Humans routinely compensate for messy data: they recognize duplicates, infer relationships, and apply judgment when systems disagree. Agents can only be as competent and safe as the context you provide—and the policies you enforce. If customer identities are fragmented, product hierarchies are inconsistent, entitlements are unclear, or consent is missing, your agents will either fail quietly or succeed dangerously.
In practice, agentic AI amplifies what was already true: the enterprise runs on data. But it makes the consequences of poor data immediate, visible, and potentially irreversible.
Why application-first breaks at agentic scale
Application-first architecture is a rational default. It emerges when business units buy or build systems to solve local problems, and IT later integrates them into an end-to-end landscape. The application becomes the locus of truth for a slice of the business.
The issue is that over time, you don’t get “a system of record.” You get many. Each application carries its own data model, naming conventions, rules, and identity logic. Integration becomes the art of reconciling differences—often through point-to-point pipelines and bespoke transformations that are costly to maintain and hard to govern.
In a human-driven enterprise, this complexity is survivable because people sit in the gaps. In an agent-driven enterprise, those gaps become failure modes. Agents must decide which record is authoritative, which attribute is current, what a customer or product actually is, and whether an action is permitted. If those answers are scattered across apps, the agent layer becomes a fragile web of exceptions.
Figure 1. AI can’t make sense of siloed enterprise data
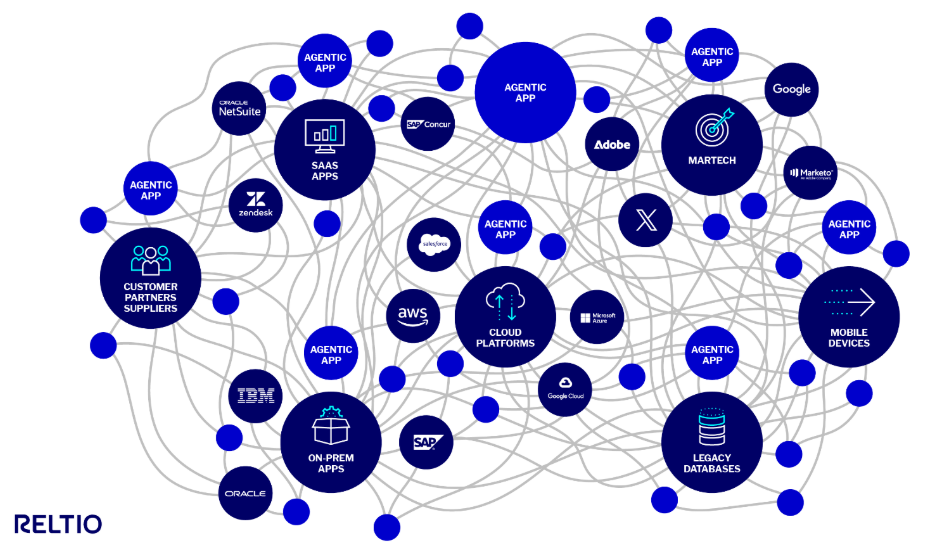
This is the hidden risk: without a coherent data foundation, your “AI transformation” can turn into a proliferation of brittle, app-specific agents that mirror today’s silos—just faster. You may automate chaos.
The operational signal to watch is integration gravity. If every new AI use case requires custom data wrangling, long cycles to align definitions, and escalating governance debates, the architecture is telling you the truth: you are not set up for agentic speed or scale.
What data-first means (and what it does not)
Data-first does not mean “build a bigger data lake” or “centralize everything.” Most large enterprises already have warehouses, lakes, and analytical platforms. Those help with reporting and historical insight, but they don’t automatically create trusted, actionable context for real-time decisions and automation.
Data-first means establishing an enterprise context layer that sits above and across applications. It does three things exceptionally well.
It establishes identity and relationships. Who is the customer across regions? How does this supplier relate to that legal entity? Which products roll up into which offering? Identity resolution and relationship mapping are not optional—they are the foundation of coordination and control.
It encodes business meaning and policy. What is the approved definition of an “active customer”? Which attributes are restricted? What consent applies? What governance rules must be enforced? In a data-first model, meaning and policy are expressed once and applied everywhere, rather than being reimplemented in each application.
It distributes trusted data to every consumer—humans, applications, and agents—in the form they need. This includes APIs, events, and data products that are observable, versioned, and governed.
A simple way to describe the shift is: in an application-first world, data is a byproduct of applications. In a data-first world, applications are consumers and curators of a shared, governed data layer.
Figure 2: The enterprise data context layer
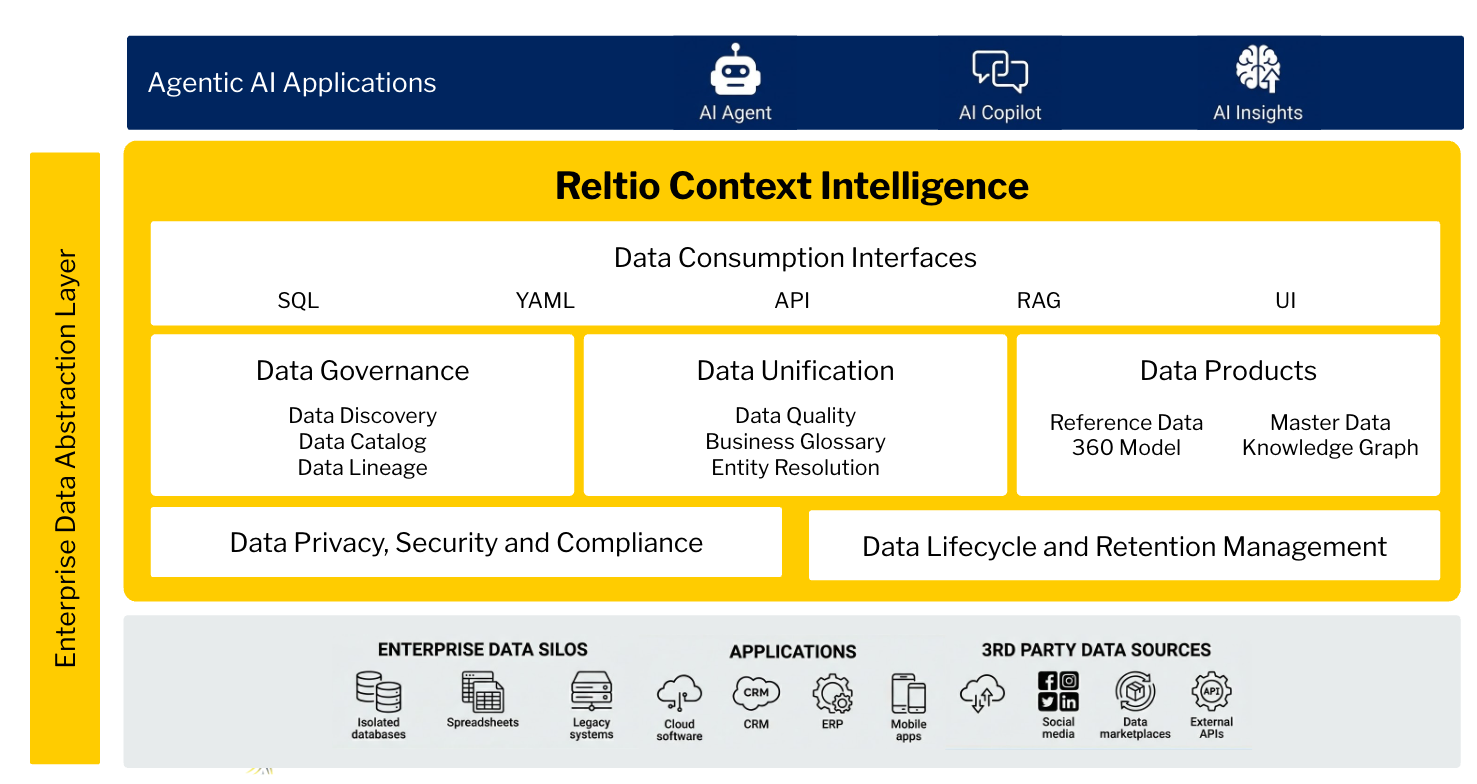
Enterprises need a complete, governed abstraction layer that sits between chaotic enterprise data silos and intelligent AI applications. It connects, governs and activates data in real-time, enabling safe and scalable multi-modal consumption via modern technology and interfaces.
The business case CEOs and boards should care about
The board-level question is not “should we modernize our data?” It is “what becomes strategically possible—or impossible—when our enterprise can’t provide trusted context at machine speed?”
A data-first architecture supports three outcomes that matter to competitiveness and growth.
- Speed to innovation matters because agentic AI compresses cycles. The companies that win will not be the ones with the most pilots; they will be the ones that can industrialize agents quickly across multiple domains. Data-first reduces time spent on reconciliation and increases the reuse of data, policies, and controls. That is what turns one-off success into an enterprise capability.
- Customer and operational advantage increasingly comes down to experience and execution: personalization, proactive service, frictionless onboarding, resilient supply chains, dynamic pricing, and faster dispute resolution. Those are cross-system outcomes. Data-first enables coherent action across channels by providing a consistent view of entities and their context.
- Risk management becomes a growth enabler, not a brake. Agents introduce a new class of risk: automated actions taken in the context of partial or incorrect information. Data-first makes controls enforceable—entitlements, consent, audit, lineage, and policy become part of the runtime fabric rather than an afterthought. This is essential for regulated industries, but it is quickly becoming table stakes everywhere.
There is also a straightforward economic argument. As enterprises scale, the most expensive “hidden tax” is not storage or compute—it is the labor and fragility of integration, reconciliation, and exception handling. Data-first reduces that tax by making trust reusable.
Feasibility: why this is achievable now
Data-first has been an aspiration for decades, but it often failed because the tooling and operating models were immature. Two changes make it materially more feasible today.
The technology stack has converged around real-time, API-driven patterns. Cloud platforms, streaming architectures, event-driven integration, and modern data management capabilities make it practical to propagate trusted data in near real-time rather than only in nightly batches. This is crucial for agentic systems that need fresh context.
The organizational model is finally catching up. Practices like domain ownership, data products, governance-as-code, and continuous delivery create a path to scale without requiring a monolithic “enterprise data program” that never finishes.
A rolling roadmap: start now, deliver value every quarter
If you are a CEO or board member, you should expect measurable progress in the first 0–90 days—not at the end of a long program. Think of this as a rolling horizon: deliver outcomes each quarter, reduce risk continuously, and build a reusable context layer that makes every new agentic workflow faster to launch and safer to run.
In the first 0–90 days, the work is mostly strategic and organizational. Align on two or three high-value workflows where agentic execution can change a business metric. Define the minimum context required for safe action, then set decision rights, policies, and success measures up front—so teams can move quickly and prove controls early.
In months three to six, deliver the first workflow end-to-end using that context. Build the initial governed data products, identity resolution where needed, and the monitoring, auditability, and guardrails that let you move fast without compromising control. The goal is a visible win in the quarter—paired with a repeatable pattern.
In months six to twelve, expand from a “golden record” to a reusable context graph that connects entities, relationships, and events across domains. Add richer metadata, lineage, and human-in-the-loop controls for higher-risk actions. Reuse should show up as shorter cycle times and fewer one-off integrations—quarter after quarter.
Beyond 12 months, scale horizontally across business units and use cases by standardizing how context is created, consumed, and measured. At this stage, the operating model matters as much as the platform—definitions, policies, and data products must be managed as shared assets, not local exceptions.
The practical checkpoint is this: each quarter should deliver a business outcome and make the next release easier. If teams are rebuilding context for each new pilot, you do not yet have a data-first foundation—you have isolated projects.
Where to balance investment in the tech stack
A common failure mode is over-investing in the “AI layer” while under-investing in the “trust layer.” Models and agent frameworks evolve quickly; the hard part is making enterprise data reliable, explainable, and governable in motion.
In a data-first program, investment typically needs to concentrate in five areas.
Identity and context management come first. This includes mastering core entities (customers, products, suppliers, patients, members, accounts, assets), resolving identity across sources, and maintaining relationships. If you cannot confidently answer “who/what is this?” your agents will not be dependable.
Integration and real-time delivery is next. Agents need fresh context and low-friction execution. That demands API management, event streaming, and a disciplined approach to data contracts. The goal is to reduce custom pipelines and create repeatable patterns.
Governance, security, and policy enforcement must be designed in from day one. Agentic AI raises the stakes on authorization, consent, and audit. Fine-grained access control, lineage, and policy-as-code should be part of the fabric, not bolted on later.
Observability and resilience become board-level requirements. When agents act, you need to see what happened, why it happened, and what data it used. Logging, monitoring, quality signals, and incident response must extend across data pipelines and AI workflows. “No surprises” becomes the standard.
The AI execution layer is the most visible but should be the most modular. This includes model access, orchestration frameworks, tool calling, prompt and workflow management, evaluation, and human-in-the-loop controls. The critical point is that this layer should be designed to swap components as the market evolves—your enduring advantage should sit in the data and policy foundation, not in a single model choice.
If you want a simple heuristic: fund the capabilities that are slow to change (identity, semantics, policy, governance, and integration patterns) so you can move fast on the capabilities that change every quarter (models and agent frameworks).
The questions that separate pilots from advantage
Most boards are now comfortable approving “AI initiatives.” The harder job is forcing clarity on how the enterprise will operationalize agentic AI safely and at scale. These questions tend to expose whether an organization is building a durable capability or just accumulating demos.
What decisions and actions are we willing to delegate to agents in the next 12 months—and what must remain human-controlled? This is not a technology question; it is a risk and accountability question.
Where does the “truth” live for our core entities? If customer, product, and supplier identity are fragmented, what is our plan to establish an authoritative context layer?
Which policies must be enforced at runtime? Think consent, entitlements, segregation of duties, and regulatory constraints. How will an agent know what it is allowed to do?
How will we measure value beyond productivity anecdotes? What operational metrics will improve—cycle time, conversion, churn, claims leakage, working capital, outage minutes, compliance exceptions—and how quickly?
What is our operating model? Who owns data products, definitions, and quality? How are conflicts resolved when business units disagree?
And finally, what is our plan for resilience and for failure? When an agent produces the wrong outcome, how will we detect it, contain it, and learn from it?
If your leadership team cannot answer these questions in a way that connects architecture to outcomes, the program is not yet board-ready.
The shift is already underway
Application-first architecture made sense in the era when software was primarily a set of user interfaces and workflows. Agentic AI is turning software into a set of coordinated actors. In that world, a company’s ability to unify identity, meaning, and policy—and to deliver that trusted context in real time—becomes the difference between scalable advantage and automated fragility.
The good news is that you do not need to “rebuild everything” to move to a data-first approach. You need a clear point of view, disciplined sequencing, and the courage to treat data as a platform capability rather than a downstream artifact.
If I were advising a CEO on one immediate step, it would be this: pick the agentic workflows that matter most, then ask your CIO/CTO to show—concretely—how the enterprise will provide trusted context, governance, and observability for those workflows. The gaps you uncover will tell you exactly where your data-first roadmap should begin.
