What is a Data Pipeline?
Data pipelines describe the sequential processes used to transform source data into data suitable for storing into target locations. The pipeline analogy illustrates the flow of data as a one way stream, which moves through various processes for cleaning and filtering but never backwards.

Understanding Data Pipelines
Raw data collected in enterprise settings can come from hundreds of internal and external sources each of which format and enforce data quality differently. Like reclamation water that must be purified by flowing through multiple scrubbers and chemical treatments before use, the enterprise’s data pipeline ensures that all raw data undergoes treatment designed to produce the same level of data quality before entering into enterprise use.
Data pipelines are a fundamental concept used in the Data Integration and Interoperability (DII) knowledge area of most data management frameworks. DII is concerned with the movement and consolidation of data within and between applications and organizations.
The general data pipeline pattern consists of data producers, data consumers, and the data pipeline that links the two. Data producers include on-premise sources, edge sources, SaaS sources, and cloud sources. Data from these sources is ingested or integrated into an operational data store where it is transformed into a format suitable to be stored in data warehouses and further used by downstream data consumers.
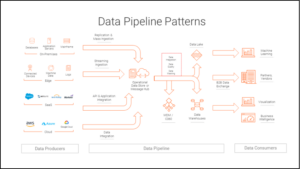
“Data Pipeline Patterns” by Informatica.com
Types of Data Sources
- On-premise sources include databases, application servers, and mainframes, many which may use SQL, Oracle, ODBC, even CSVs to store data.
- SaaS APIs are also a common data source. Application Programming Interfaces (APIs) allow systems to speak a common language, the API language, and work together without having to reveal their inner workings to each other.
- Edge computing encompasses IoT devices and peripheral systems. The Edge provides access to sensor devices away from the central system where data is processed near or on the sensor device (data processing where data is generated), in order to speed response time, for example, in cases such as in self-driving automobiles when latency risk is too great. These sources can send summary data back to central systems after local processing.
- Cloud data sources, like data exchanges, offer enterprises access to data sources beyond their reach that can be integrated into their operations, including public data sets, social media, marketing data, or partner data warehouses and data lakes.
Data pipelines are designed to form the foundation to other data projects, like:
- B2B data exchanges are industry standardized data exchanges that allow the sharing of operational data between vendor partners.
- Business intelligence and data visualizations are critical avenues for downstream data consumption, providing much needed understanding about business trends, and most importantly insight into the business itself with actionable information.
- Machine learning applications use AI techniques that automate analytical model building to construct predictive models, which anticipate questions like customer behavior patterns, and prescriptive models, which anticipate changes and risks to form recommendations to future potential business outcomes.
In short, data pipelines are patterns of data movement, but also a term that refers to the solutions employed in automating data integration and interoperations.
Types of Data Pipelines
Two common types of data pipelines are in popular use today, streaming data processing, and the ubiquitous batch processing.
Batch Processing
Most data moves between applications and organizations as files or chunks of data on request or periodically as updates. This process is known as a batch or sometimes ETL. The batch is usually very large, and requires significant time to transfer and resources to process, therefore it is often performed during off-peak hours when compute resources can be wholly dedicated to the job. Batch processing is often used for data conversions, migrations, and archiving, and is particularly useful in processing huge volumes of data in short time frames.
Batches are processed in one go which entails synchronization risks where one system that is periodically updated by batch processes becomes out of sync until the update batch is completed. But, there are many techniques to mitigate this risk, including adjusting batch frequency, using a scheduler, and the use of micro-batches.
Streaming Data
Some systems too critical to business operations cannot be subject to latency, for example, ordering and inventory systems that could be processing thousands of transactions an hour. This scenario calls for real-time, synchronous solutions. In streaming data processing, or target accumulation, the target system does not wait for a source-based scheduler, instead, it will accumulate data into a buffer queue and process it in order.
Data Pipeline Architecture
Data pipeline architecture refers to the design of the systems that form the data pipeline. Data pipelines are composed of four general components.
- Data Sources — Data sources include APIs, on-premise systems, Cloud, and Edge.
- Business Logic Rules — The actual processes and logic the business undergoes in its day to day that it needs data for. These rules are written down, but they are not computer code, instead they are used to configure the data pipeline’s filters, etc., for example, a business rule may say purchases of $500 or more must be flagged for approval before acceptance.
- Data Destination or Target Sources — Common targets are data warehouses and data lakes.
- Scheduler or Orchestration Tool — Schedulers control the frequency timing for initiating batches. An orchestration tool, or workflow orchestrator, is a overarching application that coordinates (“orchestrates”) processes and timings between several systems.
Building a Data Pipeline
Creating a high-performing data pipeline involves a structured, multi-phase approach that ensures data flows smoothly and is prepared for analysis and consumption.
- The first phase involves organizing and managing data through a centralized catalog and governance framework, which helps enforce data compliance, ensure consistency, and provide secure, scalable access across the organization.
- Next comes the data ingestion stage, where information is pulled from diverse sources including legacy on-premise systems, cloud-based applications, IoT devices, and real-time data streams and loaded into a centralized data lake for processing.
- Once ingested, the data enters a transformation process where it is cleaned, enriched, and restructured. This stage often uses a zoned architecture, with areas such as staging, enrichment, and enterprise zones to manage the progression from raw to curated data.
- After transformation, data quality controls are applied to maintain integrity, reliability, and consistency. These quality checks help ensure that only validated, trustworthy data is made accessible to users across departments, supporting efficient data operations practices.
- The next step is data preparation, where the refined and validated datasets are pushed to a data warehouse to support self-service analytics, reporting, and advanced data science projects.
- Finally, stream processing capabilities are incorporated to handle high-velocity data. This allows organizations to analyze events and transactions in real time, delivering timely insights while feeding the processed data into a warehouse for broader analytical consumption.
Together, these stages form a cohesive pipeline that transforms raw data into actionable intelligence efficiently and at scale.
Benefits of Data Pipelines
Data pipelines offer a range of powerful benefits that are foundational to modern data management, analytics, and digital transformation. As organizations grapple with increasing volumes, varieties, and velocities of data, well-designed data pipelines provide the automation, scalability, and control needed to transform raw data into usable, high-quality insights. Their ability to streamline data movement and processing across systems is essential for enabling data-driven decision-making, improving operational efficiency, and supporting real-time applications.
One of the most significant benefits of data pipelines is automation. Traditionally, moving data between systems required manual effort which were time-consuming, error-prone, and difficult to scale. Data pipelines automate these processes, ensuring data flows from source to destination reliably and repeatedly. This not only reduces the burden on IT and data teams but also improves consistency and timeliness. Automation enables near real-time data ingestion, transformation, and delivery, critical for supporting dashboards, monitoring systems, and machine learning models that rely on the latest information.
Data pipelines also improve data quality and consistency. As data moves through a pipeline, it undergoes transformations such as cleansing, normalization, validation, and enrichment. These processes ensure that data adheres to defined standards and business rules, reducing the risk of inaccuracies that could compromise analytics or lead to flawed decision-making. Pipelines often include automated checks and error handling mechanisms that catch and flag anomalies, further enhancing trust in data assets. Consistent, high-quality data is vital for maintaining the credibility of business intelligence tools and ensuring regulatory compliance.
Another key benefit is scalability and flexibility. Data pipelines are designed to handle large volumes of data from various sources and formats, whether structured, semi-structured, or unstructured. They can scale horizontally to accommodate increasing workloads without major infrastructure changes. This is particularly important in big data and real-time analytics environments where the volume and speed of data can fluctuate rapidly. With modern, cloud-native pipeline architectures, organizations can scale ingestion, transformation, and processing dynamically based on demand.
Data pipelines also support data integration and unification across disparate systems. In many organizations, data resides in silos spread across CRMs, databases, data lakes, SaaS applications, and IoT platforms. Pipelines connect these sources, bringing together data from different departments and formats into a centralized, coherent repository such as a data warehouse or data lake. This integration is essential for creating a single source of truth, enabling comprehensive analysis, cross-functional reporting, and more effective decision-making across the enterprise.
In addition, pipelines enhance agility and time-to-insight. By automating and streamlining data workflows, pipelines drastically reduce the time it takes for raw data to become analytics-ready. This accelerates the feedback loop between data collection and business action, empowering teams to make faster, more informed decisions.
Operational efficiency and cost savings are additional benefits. By automating routine data movement and transformation tasks, pipelines reduce the need for manual intervention, thereby lowering labor costs and minimizing the risk of human error. They also optimize resource utilization especially in cloud environments by dynamically scaling compute and storage resources to meet demand. Moreover, data pipelines reduce duplication of effort and make it easier to reuse data assets across different teams and applications.
Finally, data pipelines contribute to stronger data governance and compliance. They allow organizations to enforce data management policies consistently, from access controls and encryption to lineage tracking and audit logging. Many pipelines are designed with built-in metadata capture, enabling visibility into how data is sourced, transformed, and used. This transparency supports compliance with regulatory requirements such as GDPR, HIPAA, and CCPA, which mandate clear data provenance and auditability.
Data Pipelines vs ETL
ETL stands for Extract, Transform, and Load, and refers to the basic pattern for processing and integrating data together from multiple sources. This pattern is used in physical as well as virtual executions, and in batch processing and real-time processing. In general, ETL data flows is a term that can be interchanged with data pipeline, however, data pipelines entail more.
A data pipeline, in comparison to ETL, is the exact arrangement of components that link data sources with data targets.
For example, one pipeline may consist of multiple cloud, on-premise, and edge data sources, which pipe into a data transformation engine (or ETL tool) where specific ETL processes can be specified to modify incoming data, and then load that prepared data into a data warehouse.
Contrastingly, another pipeline may favor an ELT (Extract, Load, and Transform) pattern, which will be configured to ingest data, load that data into a data lake, then transform it at a later point. However, ETL is the more common approach rather than ELT, and so easily associated with data pipelines.
Data Pipeline Use Cases
Data pipelines serve as the backbone of modern data infrastructure, enabling the automated and efficient movement of data from various sources to designated storage or processing destinations. Their utility spans a wide range of operational and analytical needs, making them critical across nearly every industry.
- Business Intelligence and Reporting: Organizations frequently extract data from systems like CRMs, ERPs, or marketing platforms, standardize and transform the data, and load it into centralized data warehouses. This process supports dashboards and reporting tools that provide executives and analysts with real-time insights and key performance indicators. For instance, a retail company may use a data pipeline to automate the daily update of sales and inventory data, ensuring decision-makers have accurate and timely information to act on.
- Real-Time Analytics and Monitoring: Businesses increasingly depend on instant access to insights from high-velocity data sources such as IoT devices, social media, or web clickstreams. This allows companies to identify and respond to anomalies or trends as they happen. A logistics company, for example, may analyze real-time GPS data to dynamically adjust delivery routes and keep customers informed of expected delays.
- Machine Learning and AI Workflows: Clean, well-labeled, and enriched data is critical for training and deploying predictive models. Pipelines can automate the ingestion and preprocessing of this data, enabling continuous model training, updating, and scoring. A financial institution may build a data pipeline to feed customer transaction data into real-time fraud detection models, allowing them to flag unusual activity the moment it occurs.
- Data Migration and Modernization: When organizations move from legacy infrastructure to cloud-native platforms, pipelines extract data from outdated systems, adapt schemas, and load it into scalable cloud environments. This enables access to advanced analytics capabilities and reduces infrastructure costs. A healthcare provider might use pipelines to migrate electronic health records into a HIPAA-compliant cloud data warehouse, improving both interoperability and accessibility.
Data Pipeline Best Practices
When building a modern data pipeline, it’s essential for organizations to follow foundational best practices during the initial planning and design stages to ensure scalability, performance, and long-term maintainability. An effective pipeline should deliver current, high-quality data, while supporting the agility needed for data operations and machine learning operations environments. This helps accelerate the delivery of insights, analytics, and machine learning outcomes.
- To support advanced analytics and AI/ML workloads, your pipeline should be architected to support cross-platform flexibility and seamless deployment across leading cloud environments. It should handle both batch processing and real-time streaming, accommodating a broad range of use cases. The ingestion process must be capable of pulling data from any source whether it’s on-premises databases, legacy applications, change data capture systems, or IoT streams and delivering it to cloud-based data warehouses or data lakes with minimal latency.
- An intelligent pipeline should also be equipped to detect schema changes like altered column types or newly added fields, in source relational databases and respond automatically by synchronizing these changes downstream, ensuring consistent data replication and supporting real-time analytics.
- To simplify development and reduce the need for manual coding, the platform should offer a visual, intuitive interface that enables configuration through guided workflows. Built-in automation capabilities such as intelligent resource provisioning, dynamic scaling, and performance tuning should optimize both design-time and run-time efficiency. Leveraging a fully managed, serverless architecture can further boost productivity by eliminating infrastructure overhead and enabling teams to focus on data rather than operations.
- Lastly, embedding data quality controls into the pipeline ensures that the data being delivered is clean, standardized, and reliable. These cleansing processes are vital for addressing common data integrity issues before the data is consumed by analytics platforms or machine learning models.
Altogether, these capabilities form the foundation for a resilient and forward-looking data pipeline infrastructure.
Ready to
see it in action?
See how the Reltio Context Intelligence Platform can give you the speed and flexibility you need to accelerate the value of your data and maximize its impact every day.